Free feature
Global datasets¶
A global dataset is a collection of data pertaining to the same concept from different sources. In other words, a global dataset combines data from sources that are semantically linked, to provide a comprehensive and logical grouping of this data into one dataset. This will reduce the total number of pipes needed compared to a system where you get data from the original sources each time.
Global datasets can be populated by:
Adding datasets to a global dataset without merging
Merging data from various source datasets without modifications
Selectively merging datasets, by choosing which properties to merge through transformations
It is important to remember that creating a global dataset requires either business knowledge or a sound understanding of the data entering Sesam from the different sources. Each global dataset should contain a specific type of data, for example a person, a location, or a contract. Business knowledge is required to make sure that the right data ends up in the right global. It is also important to avoid accidentally overwriting data by ingesting data many-to-one. Consider a location global that takes in cities from one source and zip codes from another. A city contains many zip codes, so if you try to add zip codes to a city, the city entity will contain only the most recent zip code. On the other hand, adding cities to zip codes works, because each zip code belongs to only one city.
Use case¶
Imagine there are three sources being ingested into Sesam, each containing person data. It is not immediately obvious which person metadata comes from which source. However, through the creation of a global-person dataset, information can be easily merged into, and fetched from, one location. Otherwise, each time person data is required it would be necessary to check all three sources individually. Take a look at the example below to get an idea of how this could be done.
HR system
{
"_id": "hubspot-person:02023688018",
"hubspot-person:EmailAddress": "IsakEikeland@teleworm.us",
"hubspot-person:Gender": "male",
"hubspot-person:Address": "Himmelberg Vei 11",
"hubspot-person:PostCode": "0166",
"hubspot-person:SSN": "02023688018",
"rdf:type": "~:hubspot:Person"
}
CRM
{
"_id": "crm-person:100",
"crm-person:EmailAddress": "IsakEikeland@teleworm.us",
"crm-person:ID:”100”,
"crm-person:SSN": "02023688018",
"crm-person:SSN-ni": "~:hr-person:02023688018",
"rdf:type": "~:crm:Person"
}
ERP
{
"_id": "erp-person:0202",
"erp-person:SSN": "02023688018",
"erp-person:SSN-ni": "~:hr-person:02023688018",
"erp-person:Age": "43",
"erp-person:Position": "Sales Manager",
"erp-person:ID:”0202”,
"erp-person:country":"NO",
"rdf:type": "~:erp:Person"
}
The dataset below is what a global dataset of the above three datasets would look after being merging on social security number (SSN).
{
"$ids": [
"~:crm-person:100",
"~:hubspot-person:02023688018",
"~:erp-person:0202"
],
"_id": "crm-person:100",
"hubspot-person:EmailAddress": "IsakEikeland@teleworm.us",
"hubspot-person:Gender": "male",
"hubspot-person:Address": "Himmelberg Vei 11",
"hubspot-person:PostCode": "0166",
"hubspot-person:SSN": "02023688018",
"crm-person:EmailAddress": "IsakEikeland@teleworm.us",
"crm-person:ID:”100”,
"crm-person:SSN": "02023688018",
"crm-person:SSN-ni": "~:hrsystem-person:02023688018",
"erp-person:SSN": "02023688018",
"erp-person:SSN-ni": "~:hr-person:02023688018",
"erp-person:Age": "43",
"erp-person:Position": "Sales Manager",
"erp-person:ID:”0202”,
"erp-person:country":"NO",
"rdf:type": [
"~:crm:Person",
"~:hubspot:Person",
"~:erp:Person"
]
}
Key benefits¶
By decoupling data from original sources, point-to-point integrations within Sesam can be avoided. Fewer overall connections results in lower maintenance costs as the number of integrated systems grows
Data in global datasets is re-used, which saves work and makes adding new integrations easier
Only one look-up, instead of having to “look for data” in various datasets
Inbound datasets can be kept raw and as identical to the real source as possible, independent of how the data will be used, thus avoiding “early binding”
Adding additional integrations can further refine the global datasets and improve data quality
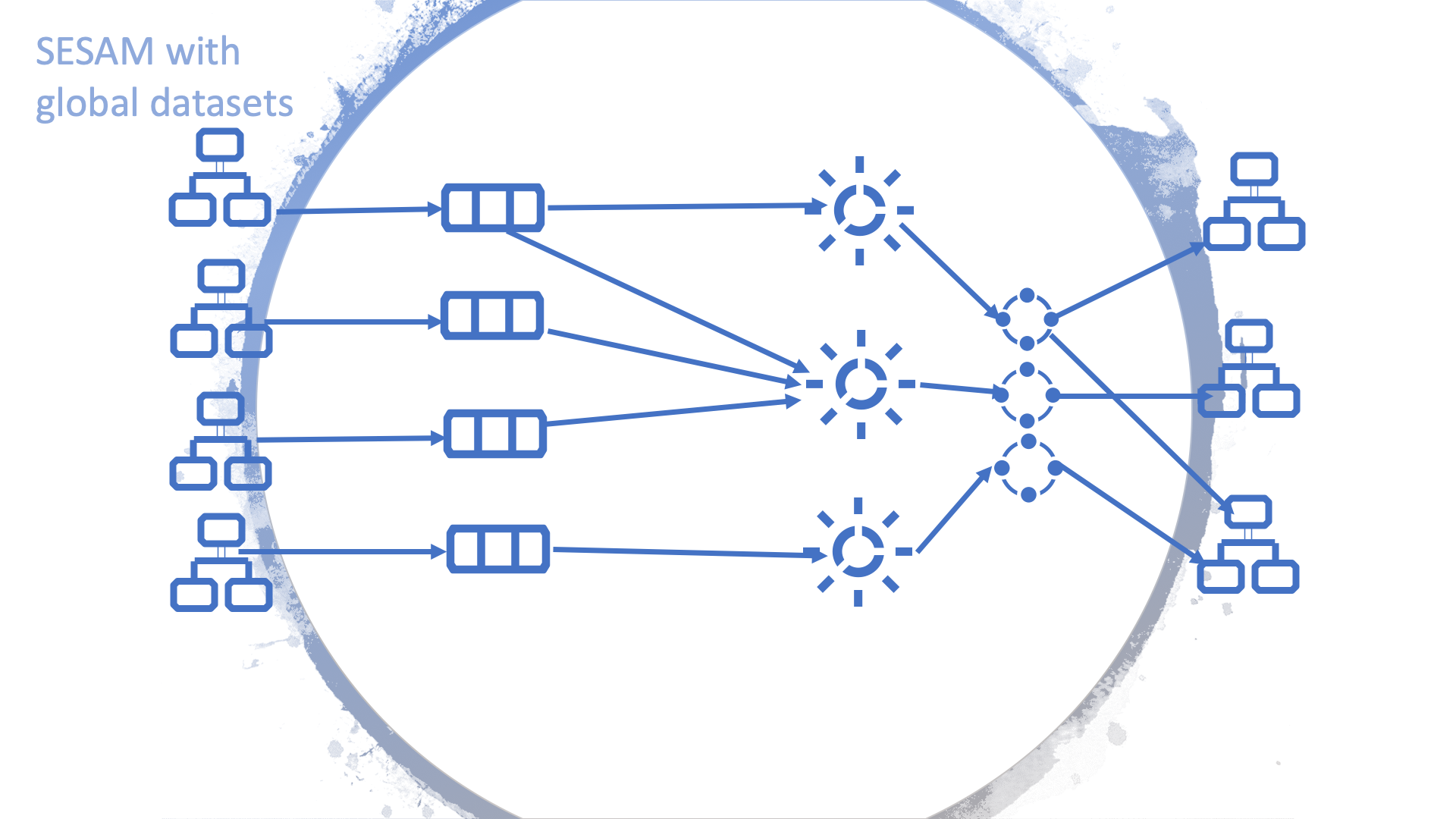
A model without global datasets might look like the figure below. This example consists of only four sources and three target systems. Generally, it will be a lot more complicated.

As shown in the figure below, a Sesam node containing global datasets results in fewer connections, making it both tidier and easier to manage.
Good to remember:
Global datasets will likely grow and become large. If the configuration or logic is changed it is possible that the whole dataset will need to be updated. This can be a big job and will take time.
As an example, an energy company has 700 000 customers, and each customer has a power meter connected to their home. When taking into account historic data, which the company is required to store as well, the company is storing data of about 30 000 000 customers. One way of managing this large amount of data is to divide the data into different global datasets. In this case, the energy company might choose to store their historic data in one global dataset, and the current data in a different global dataset.