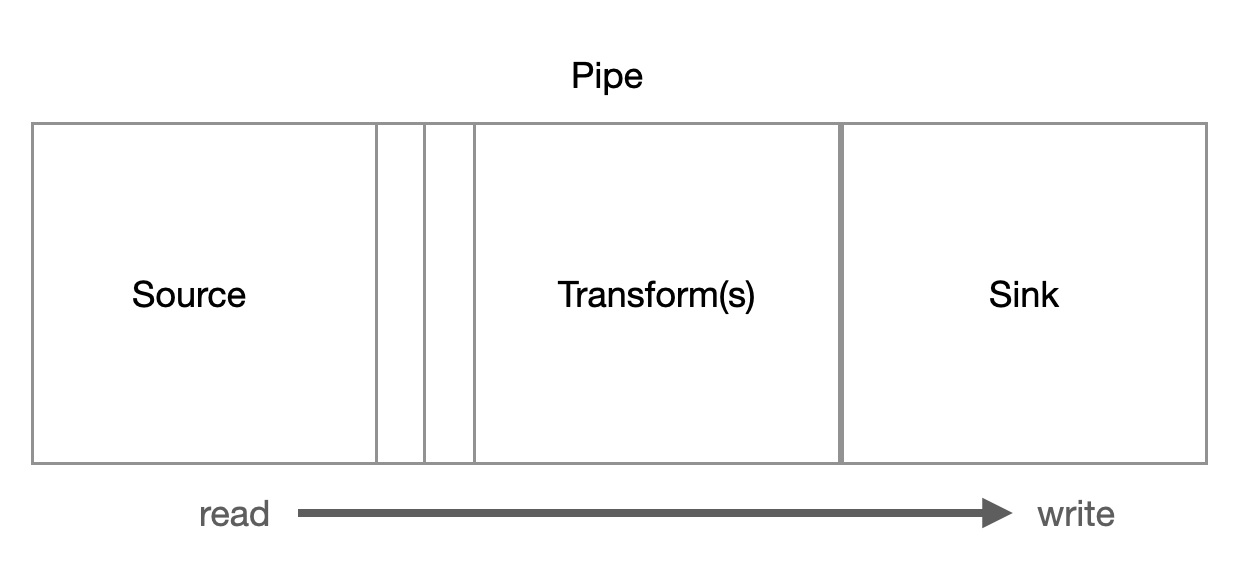
Pipes¶
A pipe is composed of a source, a chain of transforms, a sink, and a pump. It is an atomic unit that makes sure that data flows from the source to the sink. It is a simple way to talk about the flow of data from a source system to a target system. The pipe is also the only way to specify how entities flow from dataset to dataset.
Sources¶
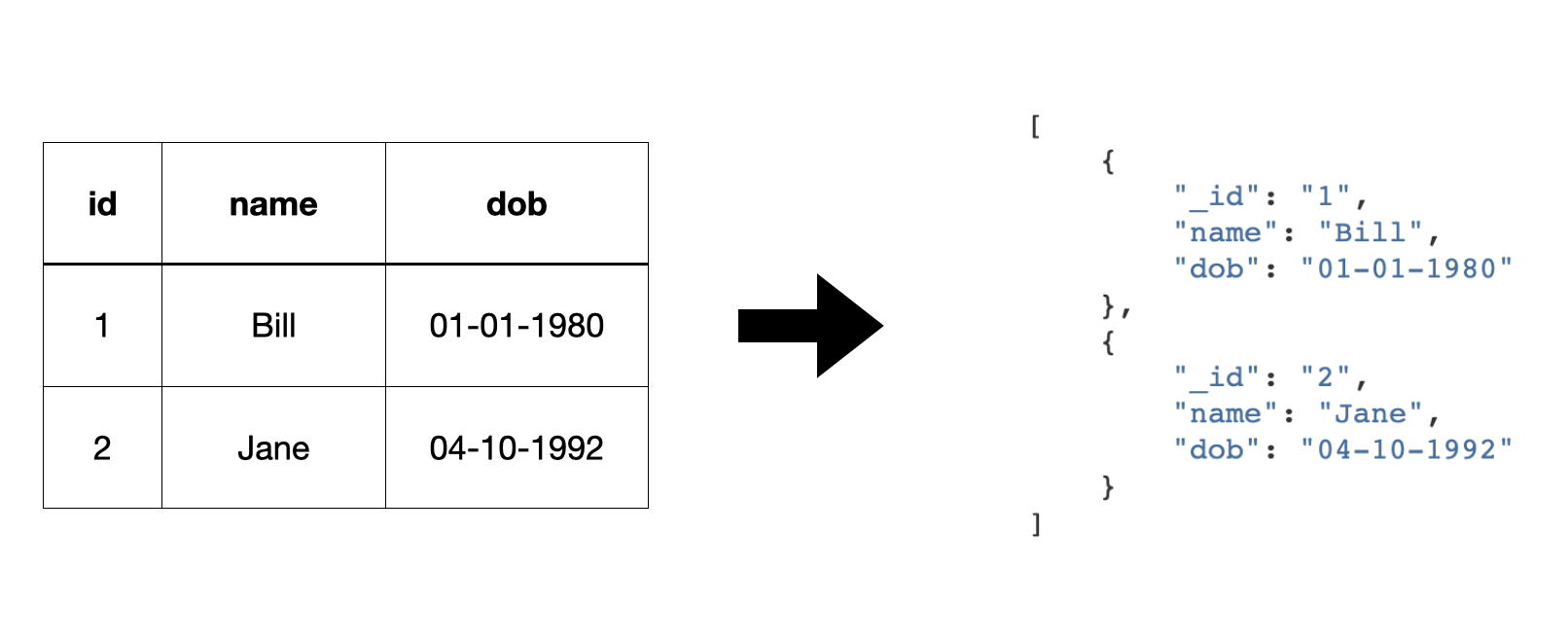
A source exposes a stream of entities. Typically, this stream of entities will be the entities in a dataset, rows of data in a SQL database table, the rows in a CSV file, or JSON data from an API.
Note
The most common source is the dataset source, which reads entities from a dataset. But there are also sources that can read data from external systems outside of Sesam.
Sources have varying support for continuations. They accept an additional parameter called a since token. This token is used to fetch only the entities that have changed since the location stored in the token. This is used to ask for only the entities that have changed since the last time Sesam asked for them. The since token is an opaque string token that may take any form; it is interpreted by the source only. For example, for a SQL source it might be a datestamp, for a log based source it might be an offset.
Sesam provides a number of out of the box source types, such as SQL and LDAP. It is also easy for developers to expose a microservice that can supply data from an external service. The built-in json source is able to consume data from these endpoints. These custom data providers can be written and hosted in any language.
To help with this there are a number of template projects hosted on ` Sesam community on GitHub <https://github.com/sesam-community>`_ to help you get started.
Transforms¶
Entities streaming through a pipe can be transformed on their way from the source to the sink.
A transform chain takes a stream of entities, transforms them, and creates a new stream of entities. There are several different transform types supported; the primary one being the DTL transform, which uses the Data Transformation Language (DTL) to join and transform data into new shapes.
DTL has a simple syntax and model where the user declares how to construct a new data entity. It has commands such as ‘add’, ‘copy’, and ‘merge’. These may operate on properties, lists of values or complete entities.
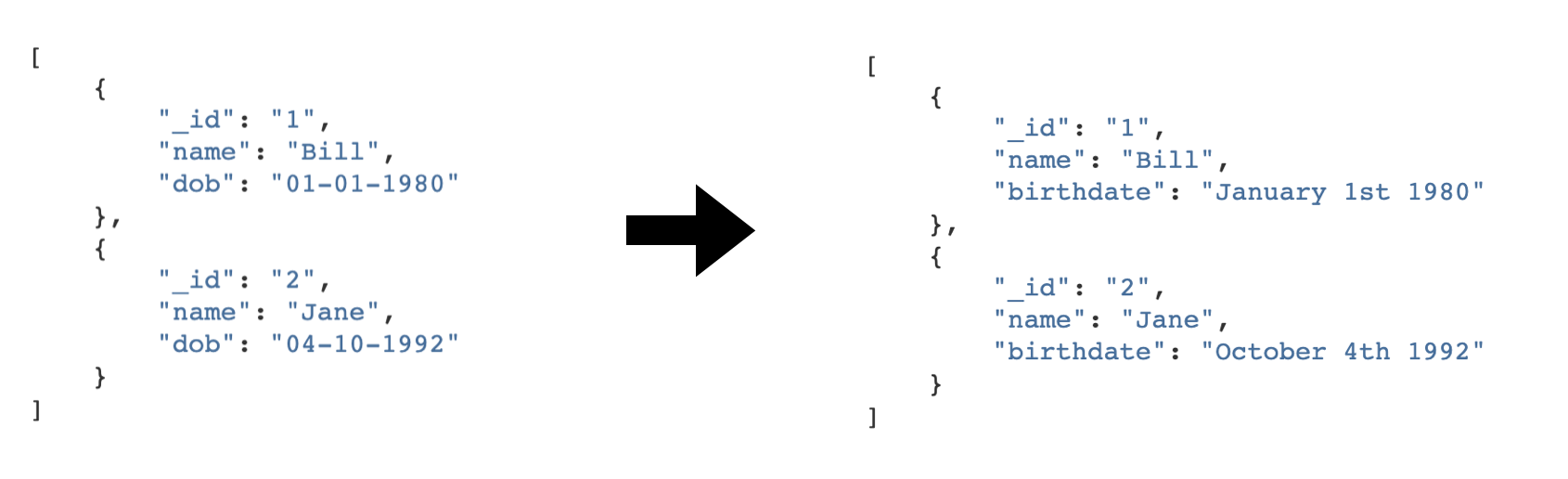
In general, DTL is applied to entities in a dataset and the resulting entities are pushed into a sink that writes to a new dataset. The new dataset is then used as a source for sinks that write the data to external systems.
Sinks¶
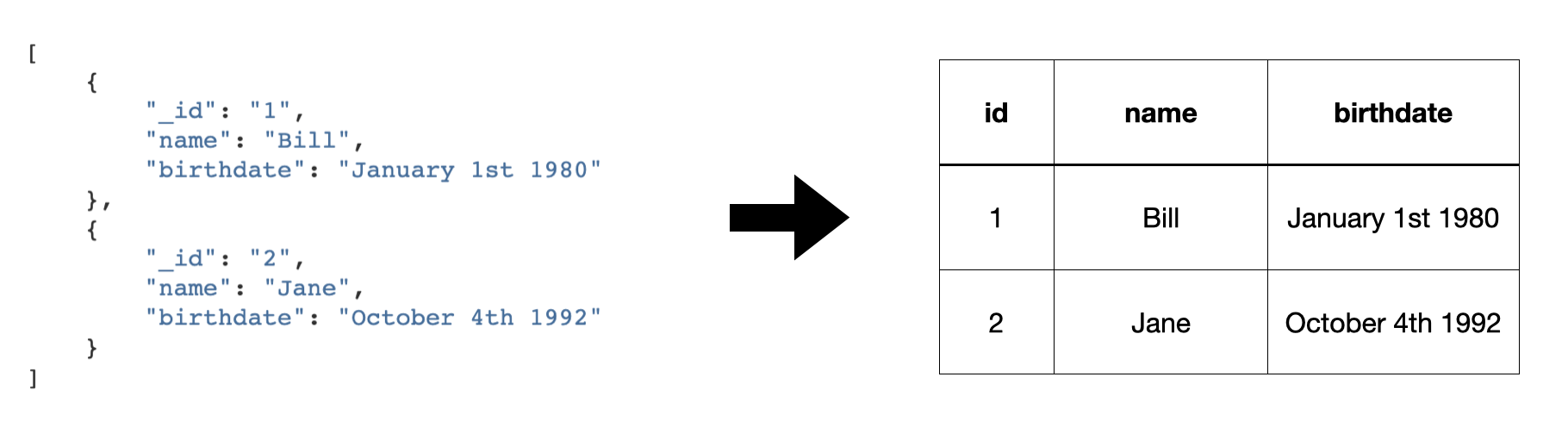
A sink is a component that can consume entities fed to it by a pump. The sink has the responsibility to write these entities to the target, handle transactional boundaries and potentially batching of multiple entities if supported by the target system.
Several types of sinks, such as the SQL sink, are available. Using the JSON push sink enables entities to be pushed to custom microservices or other Sesam service instances.
Note
The most common sink is the dataset sink, which writes entities to a dataset. But there are also sinks that can write data to external systems outside of Sesam.
Pumps¶
A scheduler handles the mechanics of pumping data from a source to a sink. It runs periodically or on a cron schedule and reads entities from a source and writes them to a sink.
It’s also capable of rescanning the source from scratch at configurable points in time. If errors occur during reading or writing of entities, it will keep a log of the failed entities, and in the case of writes it can retry writing an entity later.
The retry strategy is configurable in several ways and if an end state is reached for a failed entity, it can be written to a dead letter dataset for further processing.